

In AI large model training scenarios, the advantages and disadvantages of cluster network architecture directly affect the performance, scalability and stability of the smart computing network.CLOS Network ArchitectureIt is a network architecture widely used in cloud data centres, smart computing centres, and high-performance computing environments. The focus of this paper is to introduce how to build different sizes of parameter-plane networks (training networks) through the CLOS architecture, another article full of dry goods, less rambling, to speak in pictures.
1,CLOS Infrastructure and Extension
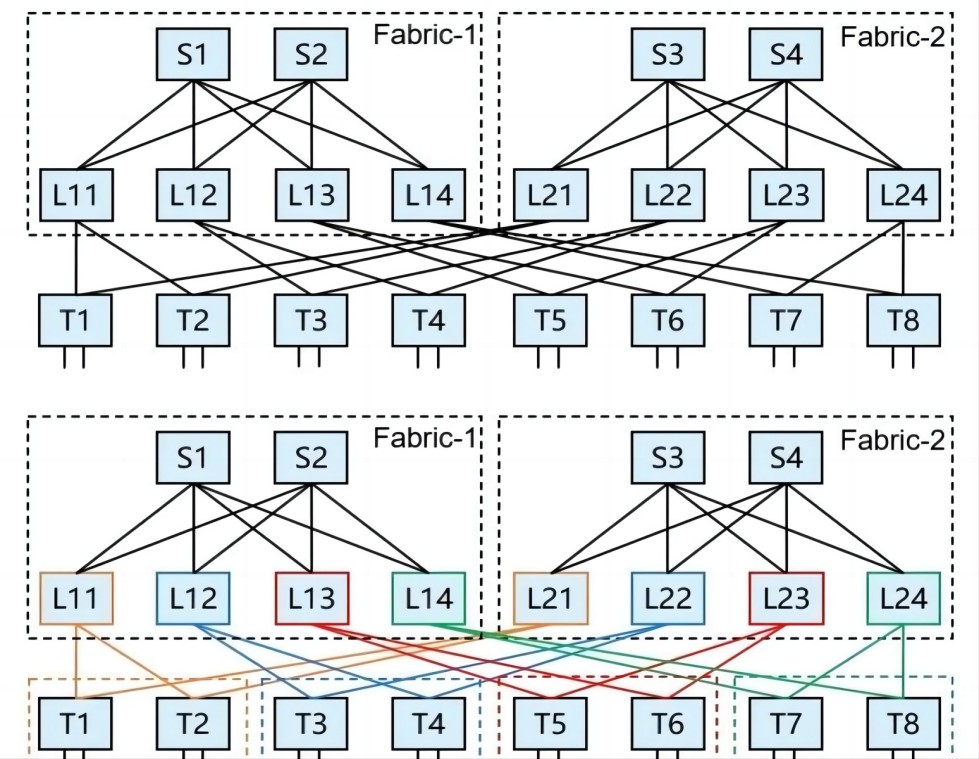
The cleanest deployment of the CLOS architecture is the Spine-Leaf two-tier network architecture.

In the classic CLOS architecture:
- All switches have the same number of ports (n) (note: in actual networking, this can also be different, and is considered here as the same)
- 1:1 convergence ratio
- Under two-layer CLOS: the maximum number of server ports to be accessed is n*n/2, with n=64, the number of server ports to be accessed is 2048

As can be seen by the two-tier networking architecture of Spine-Leaf above:
- The number of servers that can be accessed is determined by the number of downlink ports on the Leaf switch and the number of Leaf switches
- The number of Spine switches is determined by the number of uplink ports on the Leaf switch
- The number of Leaf switches is determined by the number of interfaces on the Spine switch
However, the number of server network ports that can be accessed under the two-tier CLOS architecture is limited, and when the network size is large, it is necessary to expand the two-tier CLOS architecture, corresponding to the two main modes of expansion, which are the expansion method based on the virtual machine frame and the expansion method based on the Pod.
2, Pod-based extension programme
Based on the Pod extension scheme, if we change a drawing method, we can follow the figure below, so that SS1 is grouped with SS3, and SS2 is grouped with SS4.

The size of the entire cluster is determined by the size of each Pod and the number of Pods.
The size of each Pod can be scaled by the Leaf-Spine Group architecture (the number of Leafs and Spines is n, and n x n Pod architectures of different sizes can be formed). 4 x 4 architecture can be used when the size is small, and when the size is large, the Leaf-Spine Group architecture can be adjusted accordingly to 8 x 8 architecture, 16 x 16, or even 32 x 32 or 64 x 64.

As an example, if a 64-portswitch (telecommunications)If a single Pod can be scaled to a 64 x 64 architecture, the network can be scaled to the following network size.

If you transform the drawing of the above picture, the following cube architecture is formed.

In the case of a convergence ratio of 1:1:
- Equal number of Spines and Leafs within each Pod
- Number of SSG groupings equal to the number of Spines within the Pod
- The maximum number of Super-Spines within an SSG packet is the same as the number of Spine uplink ports within a Pod
3, Extension approach based on virtual machine frames
The extension based on VM frames will also be easier to understand if we change the way we draw them.

As an example, with a 64-port switch, the cluster could scale to the following network size.

If it is also transformed into a cube architecture, as shown below:

4, Networking changes in the case of track optimisation
Some changes in the CLOS architecture extension in the case of track switching, users will adjust accordingly to their actual needs, there are many forms of changes, here are 2 examples.
Still using the 64-port switch as an example, in the case of rail switching, the Pod-based expansion changes to the following pattern:

The above diagram of the grouping in the case of track swapping is exactly the same as the standard Pod-based extension if you change the drawing style and draw Spine and Leaf together on the same track within the same Pod.

Below is an example of a NVIDIA SU (i.e. Scalable Unit, each SU contains a certain number of node-servers, here is an example of an 08Host H100 server, a SU contains 3208Host H100 server, 256 GPUs) as the base basic unit for networking, which is an example of scaling based on the virtual machine frame approach.

5,Difference between VM box based extension and Pod based extension
We put the two sets of extension diagrams together, we will find that if the middle layer of the switch based on the virtual machine box extension of the one-to-one correspondence to each Pod, it is basically no difference with the Pod-based extension, although the design concept is different, but the same way.

In terms of application scenarios, virtual machine box-based expansion focuses on scenarios running a single application, and Pod-based expansion mode focuses on scenarios distinguishing user instances. When a large-scale network is fully established, the overall size of the switches used in the two expansion modes is basically the same, and the input costs are comparable; if the construction is gradually promoted, the initial construction cost of the Pod-based expansion mode is relatively low.
Statement | The public number of articles for communication and learning only, mainly for my study notes and summaries, part of the content excerpts from other articles or other articles summarised by the original author or the original source of copyright, this public number is committed to protecting the copyright of the original author, if the source of the wrong label or infringement of your rights and interests, please contact us in a timely manner to deal with.