

大規模言語モデル(LLM)のパラメータ数が数兆に達すると、そのトレーニングは非常に困難になる。Closネットワークに基づく「レール最適化」アーキテクチャのような従来のデータセンターネットワーク設計は、any-to-anyの接続性を提供しますが、大規模なLLMトレーニングに対応するには非効率的でコストがかかります。
MITのコンピュータサイエンス・人工知能研究所(CSAIL)は、Meta Platforms社と共同で、従来のネットワークコストと比較して、同じトレーニング性能を維持しながらネットワークコストを削減できる設計である、スイッチSpineレイヤーを削除した画期的なアイデア、Rail-onlyネットワークアーキテクチャを考案した。GPUデータセンターでは、ネットワークコストは38%から77%に削減され、ネットワーク消費電力は37%から75%に削減されます。

コンテキスト
クロス・ネットワークは、データセンター内のノード(GPU、DPUなど)間の完全な接続性を実現する効率的なネットワーク・アーキテクチャ設計で、どのノードも他のすべてのノードと通信することができます。しかし、クロス・ネットワークは全ノード間の接続性を実現する唯一の方法ではありません。現在のスーパーコンピューティングセンターでは、Dragonflyトポロジーも一般的なオプションです(Google Aquilaなど)。
トンボ・トポロジーには独自の利点があるが、重大な欠点もある。具体的には、新しいマシンをネットワークに追加する必要がある場合、トンボ・トポロジーでは通常、ネットワーク全体の再構成と再接続が必要となり、運用に複雑さとコストの両方が加わる。対照的に、Closネットワークでは、ノードの追加や接続がより簡単に行える。
しかし、Closネットワークは完璧ではない。トンボのネットワークと比較すると、Closネットワークは、ネットワーク間で一貫したレイテンシーを提供するという点では、若干劣るかもしれない。全体として、どちらのアプローチにも長所と短所がある。
何兆ものパラメーターを持つ大規模なモデルを比較的タイムリーに学習させるためには、大規模なAI学習システムに約24,000~32,000個のGPUが必要であることはよく知られている。
現在、Llama 3.1 405Bモデルのトレーニングに使用されているMeta Platformsのシステムには24,576のGPUが搭載されており、次世代モデルでは32,768のGPUが1つのクラスタに搭載されると予想されている。
クロスのネットワークは、イーサネットのリーフスイッチとスパインスイッチをベースにしており、これらはすべてリモートダイレクトメモリアクセス(RDMA)をサポートしているため、GPUはこのAll-to-Aalトポロジーを使用して、ネットワーク内の他のすべてのGPUと同時にデータを共有することができます。
32,000以上のGPUを接続するための広帯域クロス・ネットワークの構築には1億5300万ドルかかり、ネットワーク全体で4.7メガワットの電力を消費する。
この論文によれば、400Gb/秒のリンクを使用して3万個のGPUを接続するクロス・ファブリックのコストは2億ドルで、ハイパースケールやクラウド・プロバイダーが4096台のサーバー・ノードを接続するのにかけるコストよりもはるかに高い。
下図は、AIクラスターの規模に応じたネットワーク・コストとネットワーク容量の相互関係を示している:
 GPUの数が2倍の65,536個になると、ポート速度400Gb/秒のネットワークのコストは3億ドルになり、約6メガワットの電力を消費することになる。
GPUの数が2倍の65,536個になると、ポート速度400Gb/秒のネットワークのコストは3億ドルになり、約6メガワットの電力を消費することになる。
プラットフォーム内接続性:高帯域幅ドメイン(HBドメイン)
リソース集約型の機械学習ワークロードの急増により、マルチGPU負荷を処理するために最適化されたGPU中心のプラットフォームが主流となっている。
これらのプラットフォームは、GPUのローカル領域内に広帯域のローカル相互接続技術を統合し、増大する通信需要に対応する。
異なるメーカー(NvidiaやAMDなど)のプラットフォームは、演算性能(FLOP)、GPUとCPUのアーキテクチャ、インターコネクト技術などの点で異なるが、すべて1つの核となる特徴を共有している:つまり、GPU間でTbpsという驚異的な内部バンド幅を実現しているのだ。
一例として、NvidiaのDGX H100サーバーは、NVSwitchを介して接続された8つのH100 GPUを統合し、7.2 Tbpsのノンブロッキング内部帯域幅を実現しています。
最近リリースされたGB200 NVL72コンピュータはさらに進化しており、第5世代のNVLinkテクノロジーを介してラック内に36個のGB200スーパーチップをGPUあたり14.4Tbpsで接続しています。
一方、AMDのMI300Xプラットフォームにはインフィニティ・ファブリックテクノロジを採用し、8台のMI300Xアクセラレータをフルメッシュトポロジで接続することで、各GPUは7.2 Tbpsの帯域幅も享受できます。さらに、NvidiaのDGX GH200のようなスーパーコンピュータは、マルチレイヤのNVSwitchトポロジでプラットフォームを256 GPUまで拡張し、完全に2分された7.2 TbpsのGPU内帯域幅を維持します。
Tbpsの内部帯域幅を持つこれらのプラットフォームは「高帯域幅(HB)ドメイン」と総称され、対応するインターコネクト技術はHBインターコネクト(HBI)と呼ばれる。
クロスプラットフォーム接続:NICドメイン
しかし、GPU中心のプラットフォームが内部帯域幅を大幅に向上させたとはいえ、単一プラットフォームを超える拡張性には限界があります。このため、通信事業者はイーサネットやインフィニバンドいわゆる「NICドメイン」は、異なるプラットフォームのNICを従来のネットワーク技術で接続することで形成される。NICドメインでは、レールに最適化されたネットワークが、特にハイパフォーマンス・コンピューティング(HPC)の分野で、高度な相互接続アーキテクチャとして広く使用されています。
Railの最適化されたネットワークは、従来のCPU中心のデータセンター・ネットワークに比べてDNNのトレーニングに適していますが、主にHPCの負荷に焦点を当てているため、LLMトレーニングのワークロードのユニークなトラフィックパターンの可能性を十分に引き出すことができません。
クロス・ネットワークのような従来のデータセンター設計は、予測不可能でバースト的なCPU集約型ワークロードの処理に重点を置いており、サーバー間に任意の接続を提供することで、複数のアプリケーション・シナリオをサポートしている。
GPUトレーニングクラスタに使用されるRail最適化ネットワークは、このデータセンター・クロスのネットワークから発展したもので、GPU負荷特性に最適化されている。Rail最適化ネットワークでは、同じローカルランクのGPUを同じRail配下のスイッチ(Railスイッチ)に割り当てることで、レイテンシを最小化する。
このレイアウトは、DNNの訓練トラフィックが非常に局所的であることを利用している。
しかし、レイルに最適化されたネットワークは、ローカル通信の待ち時間を短縮するという点では優れているが、個々のレイル・スイッチを接続するためにスパイン・スイッチ・レイヤーに依然として依存しており、完全に二分されたクロス・ネットワーク・トポロジーを形成している。
この設計により、異なるHBドメインのGPUが数百Gbpsで通信できることが保証される。しかし、スパイン・スイッチが本当に必要かどうかは、熟考する価値がある。 LLM伝送モードの解析
LLM伝送モードの解析
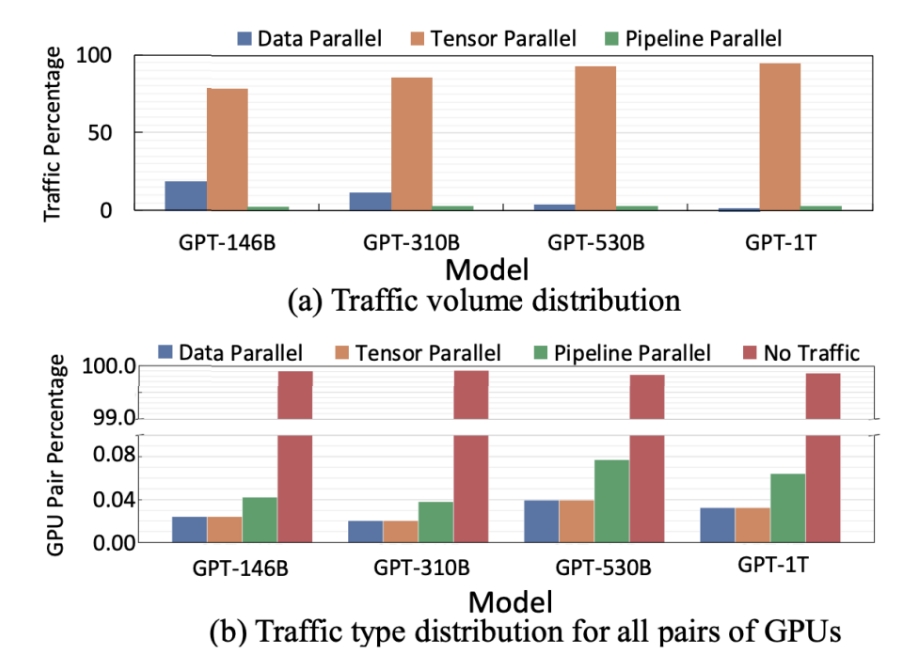
MegatronLM論文のGPTモデルを参照し、最大3072GPUと384DGX A100サーバーのクラスタ上で、パラメータサイズを変えたモデルの並列化戦略とトラフィック特性を調査した。以下は、メガトロンGPT-1Tモデルのトラフィック・パターンをさらに詳しく分析したものである: テンソル並列(TP)トラフィックは主にHBドメイン内で発生し支配的であるのに対し、データ並列(DP)とパイプライン並列(PP)トラフィックは発生頻度が低く、主にNICドメイン内のトラック内で伝送されることがわかった。
テンソル並列(TP)トラフィックは主にHBドメイン内で発生し支配的であるのに対し、データ並列(DP)とパイプライン並列(PP)トラフィックは発生頻度が低く、主にNICドメイン内のトラック内で伝送されることがわかった。
HBドメインではトラフィックが密集し、NICドメインではトラフィックが少なく、そのほとんどがトラックに限られている。
さらに、MoEレイヤーのLLMでは、トラフィックパターンは全対全トラフィックとして振る舞いますが、賢明なGPUマッピングとレイヤードアグリゲート通信アルゴリズムによって最適化することができます。
TPであろうとDPであろうとPPであろうと、トラフィックがスパイン・スイッチに行くことはほとんどない。だから、できることはネットワークの頭を切り落として、スパインのアグリゲーション・スイッチを完全に取り除くことだけだ!
鉄道のみのネットワーク設計
従来のRailに最適化されたGPUクラスタと比較して、Railのみのネットワークは、HBドメインとRailスイッチを保持し、Spineスイッチを微妙に削除している。
この変更により、同一ネットワーク内のGPUペア間の帯域幅が一定に保たれ、ネットワークファブリックの合理化とコスト削減が可能になります。
具体的には、スパインスイッチを取り除き、RailスイッチとGPU間のリンクを再構成することで、各Railが独立して動作する専用の独立したClosネットワークを構築した。RailスイッチにはGPUに直接接続するための予備のダウンリンクポートがあるため、Railのみの設計は、Railに最適化されたネットワークと比較して、必要なスイッチの数を大幅に削減し、ネットワーク全体のコストを削減します。 Rail-onlyネットワークでは、異なるHBドメイン間の直接接続は取り除かれるが、HBドメイン内の転送を通じて、ドメイン間でデータを通信することはできる。
Rail-onlyネットワークでは、異なるHBドメイン間の直接接続は取り除かれるが、HBドメイン内の転送を通じて、ドメイン間でデータを通信することはできる。
たとえば、上図で GPU 1(ドメイン 1)が GPU 2(ドメイン 2)にメッセー ジを送信する場合、メッセージはまず最初の HB ドメインを経由してドメイン 2 の GPU の 1 つに到着し、その後ネットワークを経由して最終的な宛先に送信されます。このルーティング方法は、帯域幅税(転送によるネットワークトラフィックの増加)を引き起 こす可能性がありますが、本稿の研究では、HBドメインとNICドメインの間の帯域幅の非対 称性により、この性能低下はほとんど無視できる程度であることを示しています。
鉄道のみのネットワークと、従来の鉄道に最適化されたネットワークのパフォーマンスを比較する。
その結果、数兆個のパラメータを持つLLMに対して、Rail-onlyネットワークを用いることで、同じ学習性能を維持したまま、ネットワークコストと消費電力を大幅に削減できることがわかった。具体的には、ネットワークコストは38%から77%に、消費電力は37%から75%に削減された。