

随着大型语言模型(LLMs)的参数量达到万亿级别,对其进行训练变得极具挑战性。传统的数据中心网络设计,如基于Clos网络的“Rail-optimized”架构,虽然提供了any-to-any的连接性,但在处理大规模LLM训练时显得效率低下且成本高昂。
麻省理工学院计算机科学和人工智能实验室(CSAIL)与Meta Platforms合作,提出了一种革命性的思路——Rail-only网络架构,删除了交换机Spine层,这种设计能够在保持相同训练性能的同时,相比传统GPU数据中心,网络成本降低了38%至77%,网络功耗降低了37%至75%。

背景
Clos网络是一种高效的网络架构设计,它能够实现数据中心内部各个节点(如GPU、DPU等)之间的全面连接,使得任何节点都能与其他所有节点进行通信。但Clos网络并不是实现all-to-all连接的唯一方法。在当前的超级计算中心中,蜻蜓拓扑是另一种常见的选择(如谷歌Aquila)。
蜻蜓拓扑具有其独特的优势,但同时也存在一些明显的弊端。具体来说,当需要向网络中添加新机器时,蜻蜓拓扑通常要求重新配置并连接整个网络,这样既增加了操作的复杂性,也提高了成本。相比之下,Clos网络能够更加轻松地实现节点的增加与连接。
然而,Clos网络也并非完美无缺。与蜻蜓网络相比,Clos网络在提供跨网络的一致延迟方面可能稍逊一筹。总体而言,两种方式各有利弊。
众所周知,大型 AI 训练系统需要大约 24,000 到 32,000 个 GPU才能相对及时地训练具有数万亿个参数的大型模型。
目前 Meta Platforms 系统中用于训练其 Llama 3.1 405B 模型的 GPU 数量为 24,576 个,预计下一代模型将在单个集群中跨越 32,768 个 GPU。
Clos 网络基于以太网Leaf和Spine交换机,所有交换机都支持远程直接内存访问 (RDMA),因此 GPU 可以使用这种all-to-al拓扑同时与网络中的所有其他 GPU 共享数据。
构建一个高带宽 Clos 网络来连接超过 32,000 个 GPU 需要花费 1.53 亿美元,整个网络本身将消耗 4.7 兆瓦的电力。
论文称,使用 400 Gb/秒链路连接 30,000 个 GPU 的Clos fabric将花费 2 亿美元,这比任何超大规模和云服务商用于连接 4,096 个服务器节点所花费的钱都要多得多。
下图展示了随着AI集群的扩大,网络成本和网络能力的相互作用:
 当 GPU 数量增加一倍至 65,536 台时,400 Gb/秒端口速度下的网络成本将达到 3 亿美元,并且将消耗约 6 兆瓦的电力。
当 GPU 数量增加一倍至 65,536 台时,400 Gb/秒端口速度下的网络成本将达到 3 亿美元,并且将消耗约 6 兆瓦的电力。
平台内连接:高带宽域(HB 域)
资源密集型机器学习工作负载的激增促使了以GPU为核心的平台成为主流,这些平台专为处理多GPU负载而优化。
这些平台在GPU的本地域内集成了高带宽的本地互连技术,以满足日益增长的通信需求。
尽管不同制造商(如Nvidia和AMD)的平台在计算性能(FLOP)、GPU与CPU架构,以及互连技术等方面各有千秋,但它们均共享一个核心特性:即在GPU间实现了Tbps级的惊人内部带宽。
举例来说,Nvidia的DGX H100服务器集成了八个通过NVSwitches连接的H100 GPU,实现了7.2 Tbps的无阻塞内部带宽。
而最近发布的GB200 NVL72计算机则更进一步,以每GPU 14.4 Tbps的速度将36个GB200超级芯片通过第五代NVLink技术连接在机架内。
AMD的MI300X平台则采用Infinity Fabric技术,在全网格拓扑中连接八个MI300X加速器,每个GPU也享有7.2 Tbps的带宽。此外,如Nvidia的DGX GH200超级计算机,通过多层NVSwitch拓扑,将平台规模扩展至256个GPU,同时保持7.2 Tbps的全二等分GPU内带宽。
这里将这些具备Tbps级内部带宽的平台统称为“高带宽(HB)域”,相应的互连技术则称为HB互连(HBI)。
跨平台连接:NIC域
然而,即便以GPU为中心的平台在内部带宽上取得了显著成就,它们仍受限于扩展至单个平台之外的能力。为此,运营商采用以太网或Infiniband等传统网络技术来连接不同平台的NIC,形成所谓的“NIC域”。在NIC域中,Rail优化网络作为一种先进的互连架构被广泛应用,尤其在高性能计算(HPC)领域。
虽然Rail优化网络相较于传统的以CPU为中心的数据中心网络更适合DNN训练,但它主要聚焦于HPC负载,未能充分挖掘LLM训练工作负载的独特流量模式潜力。
传统数据中心设计,如Clos网络,专注于处理不可预测和突发的CPU密集型工作负载,通过提供服务器之间的任意连接来支持多种应用场景。
而GPU训练集群所采用的Rail优化网络,正是从这种数据中心Clos网络发展而来,并针对GPU负载特性进行了优化。在Rail优化网络中,具有相同局部秩的GPU被分配至同一Rail下的交换机(Rail交换机),以最小化延迟。
这种布局充分利用了DNN训练流量的高度局部性特点。
然而,尽管Rail优化网络在降低局部通信延迟方面表现出色,但它依然依赖于Spine交换机层来连接各个Rail交换机,形成完全二分法的Clos网络拓扑。
这种设计确保了不同HB域中的GPU能以数百Gbps的速率进行通信。但值得深思的是,Spine交换机是否真的是必要的? LLM传输模式分析
LLM传输模式分析
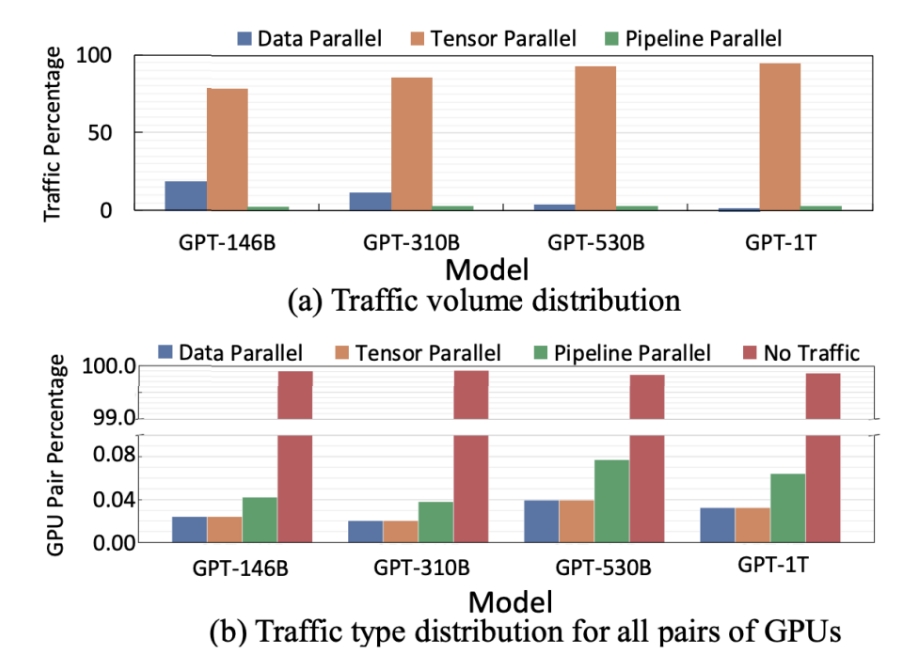
通过参考MegatronLM论文中的GPT模型,研究了不同参数规模的模型在多达3072个GPU和384台DGX A100服务器集群上的并行化策略和流量特性。以下是对 Megatron GPT-1T 模型的流量模式的进一步深入分析: 研究发现,张量并行性(TP)流量占据主导地位,主要发生在HB域内,而数据并行性(DP)和流水线并行性(PP)流量较少,主要在NIC域内的轨道内传输。
研究发现,张量并行性(TP)流量占据主导地位,主要发生在HB域内,而数据并行性(DP)和流水线并行性(PP)流量较少,主要在NIC域内的轨道内传输。
HB域内流量密集,NIC域内流量较低且主要限制在轨道内。
此外,对于MoE层的LLM,其流量模式表现为all-to-all流量,但同样可以通过合理的GPU映射和分层集合通信算法优化。
无论是TP、DP还是PP,流量很少会进入那些Spine 交换机。所以你能做的就是砍掉网络的头部,彻底摆脱Spine聚合交换机!
Rail-only网络设计
相较于传统的Rail-optimized GPU集群,Rail-only网络保留了HB域和Rail交换机,但巧妙地移除了Spine交换机。
这一变革确保了同一网络内的GPU对之间的带宽保持不变,同时实现了网络fabric的精简与成本的降低。
具体来说,通过移除Spine交换机并重新配置Rail交换机与GPU之间的链路,我们构建了一个专用且独立的Clos网络,每个Rail独立运行。由于Rail交换机拥有富余的下行端口直接连接GPU,相较于Rail-optimized网络,Rail-only设计显著减少了所需交换机的数量,从而降低了整体网络成本。 在Rail-only网络中,不同HB域之间的直接连通性被移除,但数据仍可通过HB域内的转发实现跨域通信。
在Rail-only网络中,不同HB域之间的直接连通性被移除,但数据仍可通过HB域内的转发实现跨域通信。
例如,上图中GPU 1(Domain 1)向GPU 2(Domain 2)发送消息时,首先通过第一个HB域到达Domain 2的某个GPU,再经网络传输至最终目的地。尽管这种路由方式可能引发带宽税(即由于转发导致的网络流量增加),但本文研究表明,由于HB域与NIC域之间的带宽不对称性,这种性能退化几乎可以忽略不计。
对比Rail-only网络与传统的Rail-optimized 网络性能。
结果表明,对于具有万亿参数的LLMs,Rail-only网络在保持相同训练性能的同时,显著降低了网络成本和功耗。具体而言,网络成本降低了38%至77%,功耗降低了37%至75%。